[ad_1]
This can be a visitor publish from Tomasz Magdanski, Director of Engineering, Asurion.
With its insurance coverage and set up, restore, substitute and 24/7 assist companies, Asurion helps folks shield, join and benefit from the newest tech – to make life a bit simpler. Day-after-day our workforce of 10,000 consultants helps practically 300 million folks world wide clear up the commonest and unusual tech points. We’re only a name, faucet, click on or go to away for all the things from getting a same-day substitute of your smartphone to serving to you stream or join with no buffering, bumps or bewilderment.
We expect you need to keep related and get essentially the most from the tech you like… irrespective of the kind of tech or the place you bought it.
Background and challenges
Asurion’s Enterprise Knowledge Service workforce is tasked with gathering over 3,500 information property from the whole group, offering one place the place all the info will be cleaned, joined, analyzed, enriched and leveraged to create information merchandise.
Earlier iterations of knowledge platforms, constructed totally on high of conventional databases and information warehouse options, encountered challenges with scaling and price as a result of lack of compute and storage separation. With ever-increasing information volumes, all kinds of knowledge sorts (from structured database tables and APIs to information streams), demand for decrease latency and elevated velocity, the platform engineering workforce started to contemplate shifting the entire ecosystem to Apache Spark™ and Delta Lake utilizing a lakehouse structure as the brand new basis.
The earlier platform was primarily based on Lambda structure, which launched hard-to-solve issues, equivalent to:
- information duplication and synchronization
- logic duplication, usually utilizing totally different applied sciences for batch and pace layer
- other ways to take care of late information
- information reprocessing issue as a result of lack of transactional layer, which pressured very shut orchestration between rewrite updates or deletions
- readers making an attempt to entry that information, forcing platform upkeep downtimes.
Utilizing conventional extract, remodel, and cargo (ETL) instruments on massive information units was restricted to Day-Minus-1 processing frequency, and the know-how stack was huge and complex.
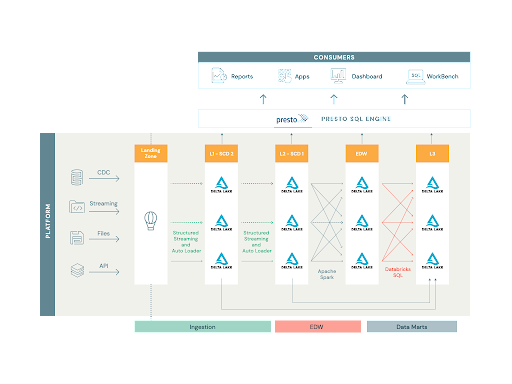
Asurion’s legacy information platform was working at a large scale, processing over 8,000 tables, 10,000 views, 2,000 stories and a couple of,500 dashboards. Ingestion information sources different from database CDC feeds, APIs and flat information to streams from Kinesis, Kafka, SNS and SQS. The platform included a knowledge warehouse combining tons of of tables with many difficult dependencies and near 600 information marts. Our subsequent lakehouse needed to clear up for all of those use circumstances to actually unify on a single platform.
The Databricks Lakehouse Resolution
A lakehouse structure simplifies the platform by eliminating batch and pace layers, offering close to real-time latency, supporting quite a lot of information codecs and languages, and simplifying the know-how stack into one built-in ecosystem.
To make sure platform scalability and future effectivity of our growth lifecycle, we centered our preliminary design phases on making certain decreased platform fragility and rigidity.
Platform fragility might be noticed when a change in a single place breaks performance in one other portion of the ecosystem. That is usually seen in carefully coupled methods. Platform rigidity is the resistance of the platform to just accept modifications. For instance, so as to add a brand new column to a report, many roles and tables need to be modified, making the change lifecycle lengthy, massive and extra susceptible to errors. The Databricks Lakehouse Platform simplified our strategy to structure and design of the underlying codebase, permitting for a unified strategy to information motion from conventional ETL to streaming information pipelines between Delta tables.
ETL job design
Within the earlier platform model, each one of many hundreds of ingested tables had its personal ETL mapping, making administration of them and the change cycle very inflexible. The purpose of the brand new structure was to create a single job that’s versatile sufficient to run hundreds of instances with totally different configurations. To attain this purpose, we selected Spark Structured Streaming, because it offered ‘exactly-once’ and ‘at-least as soon as’ semantics, together with Auto Loader, which tremendously simplified state administration of every job. Having mentioned that, having over 3,500 people Spark jobs would inevitably result in an identical state as 3,500 ETL mappings. To keep away from this downside, we constructed a framework round Spark utilizing Scala and the basics of object-oriented programming. (Editor’s be aware: Since this resolution was applied, Delta Reside Tables has been launched on the Databricks platform to considerably streamline the ETL course of.)
We’ve created a wealthy set of readers, transformations and writers, in addition to Job lessons accepting particulars by run-time dependency injection. Due to this resolution, we are able to configure the ingestion job to learn from Kafka, Parquet, JSON, Kinesis and SQS into a knowledge body, then apply a set of widespread transformations and at last inject the steps to be utilized within Spark Structured Streaming’s ‘foreachBatch’ API to persist information into Delta tables.
ETL job scheduling
Databricks recommends operating structured streaming jobs utilizing ephemeral clusters, however there’s a restrict of 1,000 concurrently operating jobs per workspace. Moreover, even when that restrict wasn’t there, let’s take into account the smallest cluster to consist of 1 grasp and two employee nodes. Three nodes for every job would add as much as over 10,000 nodes in complete and since these are streaming jobs, these clusters must keep up on a regular basis. We wanted to plan an answer that may stability price and administration overhead inside these constraints.
To attain this, we divided the tables primarily based on how regularly they’re up to date on the supply and bundled them into job teams, one assigned to every ephemeral pocket book.
The pocket book reads the configuration database, collects all the roles belonging to the assigned group, and executes them in parallel on the ephemeral cluster. To hurry the processing up, we use Scala parallel collections, permitting us to run jobs in parallel as much as the variety of the cores on the motive force node. Since totally different jobs are processing totally different quantities of knowledge, operating 16 or 32 jobs at a time supplies equal and full CPU utilization of the cluster. This setup allowed us to run as much as 1,000 slow-changing tables on one 25 node cluster, together with appending and merging into bronze and silver layers within the foreachBatch API.
Knowledge marts with Databricks SQL
We’ve an utility the place enterprise customers outline SQL-based information transformations that they need to retailer as information marts. We take the bottom SQL and deal with the execution and upkeep of the tables. This utility should be accessible 24×7 even when we aren’t actively operating something. We love Databricks, however weren’t thrilled about paying interactive cluster charges for idle compute. Enter Databricks SQL. With this resolution, SQL Endpoints gave us a extra engaging value level and uncovered a straightforward JDBC connection for our user-facing SQL utility. We now have 600 information marts and are rising extra in manufacturing in our lakehouse.
Abstract
Our engineering groups at Asurion applied a lakehouse structure at massive scale, together with Spark Structured Streaming, Delta Lake and Auto Loader. In an upcoming weblog publish, we’ll talk about how we encountered and resolved points associated to scaling our resolution to fulfill our wants.
[ad_2]